運營智慧導讀數據分析
智慧數據源于大數據且是大數據的組成部分,具體是利用數智技術有效處理、分析海量多源異構的大型數據集,產生呈現多模態、多粒度、強操作性、精確性、高價值等特征的多源融合數據(即智慧數據),智慧數據經數據消費后與其他多源異構數據共同構成大數據,隨著領域應用深化與數智技術發展實現智慧數據迭代。智慧數據由動態化的流通轉化過程形成,首先是通過數據采集環節獲取由各領域業務活動產生的多源異構、價值密度低的原生數據,其次通過原生數據處理環節產生具備可解釋性、開放性、相關性的中間數據,通過中間數據分析環節產生可推理、情境化的智慧數據。智慧數據用于智能完成具體業務領域下的特定任務,具體是將適配各業務場景的多維度標簽、目錄體系嵌入數智技術賦能的業務流程,智能感知業務需求后動態調用智慧數據以提供規律揭示、問題推理、循證溯源、趨勢預測等智能服務,由此實現智慧數據專業化、垂直化的領域精細應用。上海半坡的數字圖書館可以提供給讀者個性化閱讀和文獻知識推薦服務。運營智慧導讀數據分析
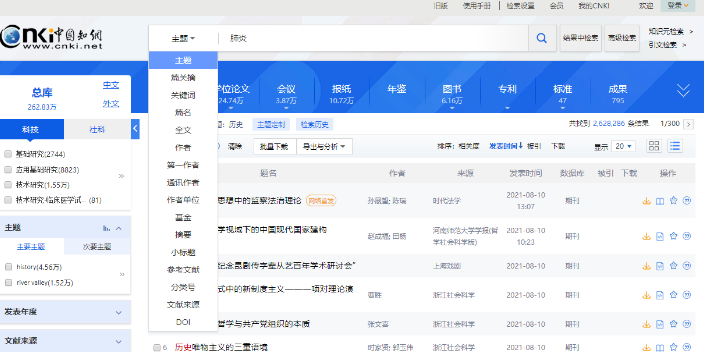
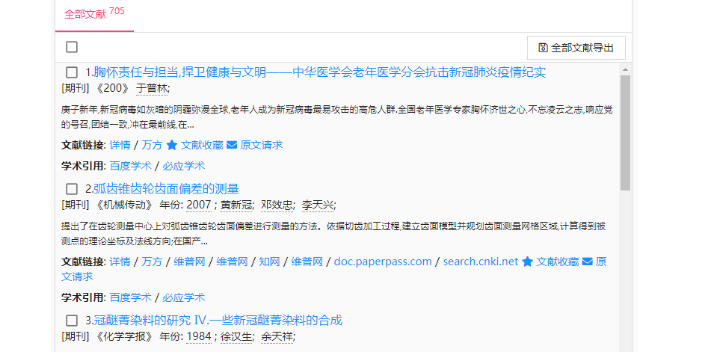
目前智慧閱讀服務的研究成果主要集中在服務系統、服務內容、用戶需求與行為等方面。面對新一代人工智能技術的不斷迭代,閱讀服務面臨前所未有的機遇與挑戰,當前學術閱讀智慧化服務存在哪些問題?如何依托AIGC技術賦能實現服務優化?這些問題亟需得到探究與明晰,但目前學界尚缺少聚焦學術閱讀智慧化服務領域的跟蹤研究。因此,本文擬利用內容分析法剖析目前國內外典型學術平臺的智慧閱讀服務現狀,總結存在問題,并探索AIGC技術賦能改進圖書館學術閱讀智慧化服務的路徑。網絡智慧導讀概況閱讀軌跡可以同時將中文與英文文獻融合生成新的語義腦圖。
信息通信技術(ICT)作為技術基座,構成信息信任系統的基礎設施。技術哲學視域下,信息通信技術不僅改變了信息供需關系,還重構了認知勞動分工。智慧閱讀依賴信息的搜索和過濾技術,它們是解決信息冗余的重要手段。不同技術對讀者的要求也不盡相同—信息搜索的質量很大程度上依賴讀者對所需信息描述的準確程度;信息的過濾則是信息供給方提供的一種服務,它從讀者的歷史行為和數據中篩選讀者感興趣的內容,**終表現為信息推薦。信息過濾的技術包括數據挖掘、知識圖譜、聚類算法、協同過濾、序列推薦、機器學習、深度學習、復雜網絡等。技術的迭代顯示機器從服從和執行人類指令過渡到有監督的學習,現在又往無監督的方向演進。算法黑箱給生產者和消費者帶來一定程度的信任剝奪,基于對信息發布主體的信任受到沖擊。
信息技術是閱讀服務創新的**驅動力,AIGC技術勢必將驅動閱讀服務的變革,促進智慧圖書館等學術平臺的服務創新。學術平臺是學術用戶明晰并滿足閱讀需求的重要支撐。目前,一些學術用戶已開始利用新型學術閱讀平臺尋求和閱讀內容,這將會對用戶學術積累方式產生影響[3]。國內外新型的學術閱讀平臺包括Scispace、SemanticScholar、YewnoDiscover、ConnectedPapers、PaperDigest、中國科學院AI引擎、AMiner、Readpaper等。相較于傳統學術閱讀平臺,它們具有典型的智能化與智慧化閱讀功能的特征。但存在一些用戶對學術平臺新功能與新服務認識不足、使用技能缺乏,學術閱讀智慧化需求得不到滿足[4],無法借助服務輔助解決學術閱讀全過程中所遇到的信息過載、交流不暢及閱讀拖延等問題。現在許多報紙都在運用這一特殊的新聞品種。
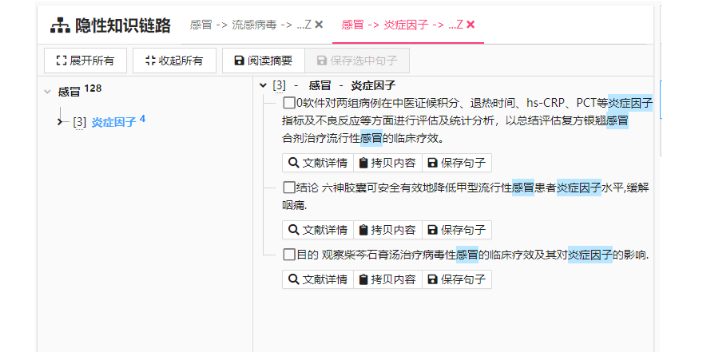
基于數據分析的結果,構建個性化的推薦算法模型。這些模型可以根據用戶的個人特征和閱讀歷史,預測用戶可能感興趣的內容,并生成相應的推薦列表。推薦算法模型需要不斷地進行優化和調整,以適應用戶閱讀行為的變化和新的數據輸入。將生成的推薦結果以合適的方式展示給用戶,如通過推送通知、郵件、APP界面等方式。同時,根據用戶的反饋和行為數據,對推薦結果進行實時調整和優化,以提高推薦的準確性和用戶滿意度。在整個過程中,需要嚴格遵守相關法律法規,保護用戶的隱私和數據安全。對用戶數據進行加密存儲和傳輸,確保只有經過授權的人員才能訪問和使用相關數據。為了給用戶提供針對性的高效知識服務,重點探討用戶閱讀行為知識。運營智慧導讀均價
上海半坡的遠程訪問服務能夠促使圖書館現有數字文獻館藏發揮更大的讀者服務效益。運營智慧導讀數據分析
隨后進行數據清洗,剔除無效、錯誤或無關數據,保證數據質量。例如,異常的用戶行為記錄、重復的條目或格式錯誤的數據都需要清理。清洗后的數據需要轉換為適合分析的格式或結構,如分類數據編碼、連續變量規范化等。這是確保數據被分析工具正確理解和處理的關鍵。在數據分析階段,通過應用統計分析、機器學習算法等,從數據中挖掘用戶的興趣和行為模式。例如,通過分析用戶的搜索和下載歷史,預測其可能感興趣的新書或主題,進而實現真正的個性化推薦。運營智慧導讀數據分析
- 遼寧智慧導讀是什么 2025-06-21
- 圖書館智慧導讀發現 2025-06-21
- 福建智慧導讀客服電話 2025-06-21
- 浙江智慧導讀服務 2025-06-21
- 江西智慧導讀大概價格多少 2025-06-21
- 數字圖書館智慧導讀有什么用 2025-06-21
- 圖書館智慧導讀承諾守信 2025-06-21
- 運營智慧導讀數據分析 2025-06-21
- 品質科研學術助手案例 2025-06-20
- 運營科研學術助手哪個好 2025-06-20
- GS驗廠LIDL驗廠驗廠申請GMI驗廠BSCI驗廠驗廠咨詢驗廠輔導 2025-06-21
- 四川質量管理QMS系統服務電話 2025-06-21
- 南京運輸膠水日本專線快遞公司 2025-06-21
- 邢臺什么公司伺服系統值得信賴 2025-06-21
- 鎮江第三方事故車托運服務電話 2025-06-21
- 杭州企業勞務派遣服務 2025-06-21
- 羅湖專業風險評估 2025-06-21
- 業務前景制造企業生產過程執行系統訂做價格 2025-06-21
- 江蘇如何專利轉讓詢問報價 2025-06-21
- 虎丘區如何專利代理哪個好 2025-06-21