國際上訊數據網關大概是
數據雷達(DR)是基于AI大模型技術的智能數據分類分級產品,能夠針對關系性數據庫、NoSQL數據庫和數據倉庫等實現元數據掃描、數據目錄構建、分類分級模型訓練和自動化識別。相比于傳統的數據分類分級產品,數據雷達產品具有如下優勢:結果更準確基于AI大模型,能夠實現同時針對數據類型在詞法、語法和語義級別的特征提取和分析,從而針對數據類型建立語義級別的高緯度特征向量,**提高了數據分類分級的準確度。可復制性更好基于AI大模型,通過針對數據字段的內容進行訓練,在不依靠數據字段的名稱和注釋的情況下就能夠達到很高的準確度,所以保證了訓練后的數據分類分級模型的可復制性。擴展性更好基于AI大模型,使用人員只需要針對一個數據類型準備幾千條-幾萬條的訓練數據就可以實現數據類型識別能力的訓練,不需要針對不同的數據類型編寫和維護。上訊數據網關產品支持數據庫客戶端的操作錄像。國際上訊數據網關大概是
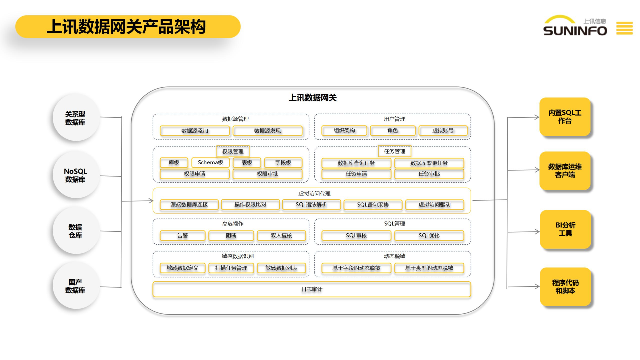
數據網關DG提供虛擬的數據訪問功能,通過字段級別的權限劃分和細顆粒度的權限管控,確保對訪問數據源的用戶進行有效的權限管理,保障數據的安全和隱私。查詢大表控制:數據網關DG能夠有效地控制對大表的查詢結果集訪問條數,優化查詢性能,確保系統穩定運行。提供內置的SQL工作臺,通過瀏覽器Web頁面對數據庫進行操作。用戶可以通過友好的圖形化界面進行數據庫查詢、修改、管理等操作,無需額外的客戶端軟件,增強了用戶操作的靈活性和便利性。客戶端和工具支持:通過使用數據網關的JDBC驅動,用戶可以在數據庫客戶端(如DBeaver、Datagrip)和BI分析工具(如SmartBI、帆軟Report)中進行數據庫操作,拓展了數據訪問和分析的應用場景。哪里上訊數據網關包含數據網關DG通過使用特定JDBC驅動實現對于數據執行SQL的獲取和代理執行。
數據雷達提供了多種分類分級算法,包括AI大模型算法、正則算法、字典算法和應用算法,旨在滿足用戶不同的分類需求,提高數據分類的準確性和效率。字典算法:(1)預定義字典算法支持:用戶可以根據預先定義好的字典算法對數據進行分類分級。這些字典可以包括行業標準術語、關鍵詞、敏感詞等,幫助用戶快速對數據進行分類。(2)自定義字段算法:支持用戶根據實際需求上傳和管理字典數據,并與算法進行關聯配置。用戶可以自定義字典內容,根據業務需求靈活管理字典數據,以滿足不同場景下的數據分類需求。(3)多算法配置:用戶可同時配置多個字典算法,并結合與、或、非等邏輯關系,實現更加復雜的數據分類分級操作。這種靈活的配置方式可以滿足用戶不同的分類需求,提升分類準確性和靈活性。
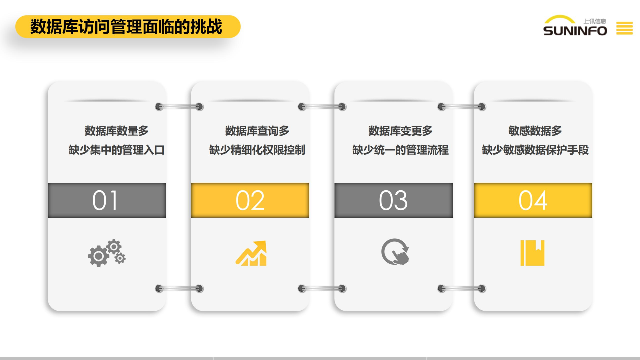
數據分類分級落地面臨的挑戰,傳統的數據分類分級技術無法滿足快速增長的大規模數據的需求。詞法分析的局限性導致數據分類分級的準確度較低,基于字段名稱和注釋的分類分級規則可復制性比較差,數據分類分級規則的編寫和維護需要大量人力介入。上訊數據雷達,基于AI的智能數據分類分級工具。自動化的數據特征提取和數據模型訓練,消除了規則的編寫和維護成本基于AI大模型,使用人員只需要針對一個數據類型準備幾千條-幾萬條的訓練數據就可以實現數據類型識別能力的訓練,不需要針對不同的數據類型編寫和維護,**降低了傳統數據分類分級技術涉及的規則編寫和維護成本。數據網關DG支持多種告警方式的配置,包括郵件告警、平臺消息告警等,以靈活滿足實際使用中的告警需求。
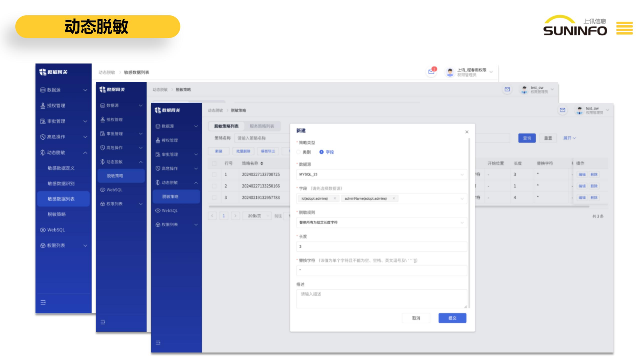
數據網管在應對網絡故障和災難恢復方面起著關鍵作用。網絡故障可能隨時發生,如硬件故障、軟件錯誤、電力中斷等。當故障發生時,數據網管需要迅速做出判斷,確定故障的類型和范圍。他們會利用各種診斷工具和技術,快速定位問題的根源。一旦確定了故障點,數據網管會采取相應的措施進行修復。這可能包括更換損壞的設備、重新配置軟件設置、恢復數據備份等。在面對重大災難,如火災、地震或網絡攻擊導致整個網絡癱瘓時,數據網管會啟動預先制定的災難恢復計劃。這個計劃包括將業務切換到備用網絡、恢復關鍵數據、重建系統等一系列復雜的操作。上訊數據網關產品支持外部應用工具通過自研訪問驅動的連接。上訊數據網關包括什么
上訊數據網關DG能夠有效地控制對大表的查詢結果集訪問條數,優化查詢性能,確保系統穩定運行.國際上訊數據網關大概是
隨著移動設備的應用,數據網管在保障無線網絡的穩定和安全方面面臨著新的挑戰。無線網絡的信號覆蓋范圍和強度直接影響用戶的體驗。數據網管需要通過合理的無線接入點布局和功率調整,確保在企業內部各個區域都能獲得穩定的無線連接。同時,他們要處理無線頻段的干擾問題,選擇合適的頻段并優化信道分配,以提高無線網絡的性能。在安全方面,無線網絡更容易受到攻擊。數據網管需要設置強密碼、啟用加密協議,并定期更新無線設備的固件,防止未經授權的訪問和數據泄露。例如,在一個大型企業園區,數據網管要確保員工在移動辦公時能夠隨時隨地連接到安全可靠的無線網絡,高效地處理工作事務,而不會因為網絡問題影響工作效率國際上訊數據網關大概是
- 長寧靜電油煙管道清洗價格 2025-07-20
- 直銷財務章服務至上 2025-07-20
- 上海朋墅轟趴介紹 2025-07-20
- 河北智能化廣告設計24小時服務 2025-07-20
- 閔行區招牌海鮮面鮮美盛宴 2025-07-20
- 昆山周市商標注冊專業代辦 2025-07-20
- 江陰品牌大件機械設備運輸便捷 2025-07-20
- 鎮江ISO13485認證標準 2025-07-20
- 靜安區物流消防檢測哪家便宜 2025-07-20
- 嘉興互聯網商城系統咨詢報價 2025-07-20