安徽智慧導讀發(fā)現
數據資源建設方面。學術平臺底層資源的數據化程度決定平臺的智慧化程度[45]。一方面,注重加強用戶學術閱讀行為數據的采集與挖掘,包括閱讀內容偏好、閱讀時長、閱讀場景、閱讀情緒、閱讀心理、社交數據等,添加基本標簽、偏好標簽、會話標簽、情景標簽、互動標簽構建用戶實時動態(tài)畫像模型。另一方面,側重開發(fā)學術資源數據,包括細粒度內容資源、個性化閱讀資源庫、科研專題資料庫、課程文獻中心等,并做好與用戶閱讀行為數據的關聯建設。例如,面向教育數字化轉型的需求,山東大學圖書館構建學術數據服務平臺,打造學者—機構—成果關聯的數據資源[46]。以這些數據為基礎,AIGC技術嵌入后將會實現多模態(tài)數據關系映射、轉換及數據感知與挖掘分析。智慧導讀可以幫助讀者更好地理解文化背景和歷史背景。安徽智慧導讀發(fā)現

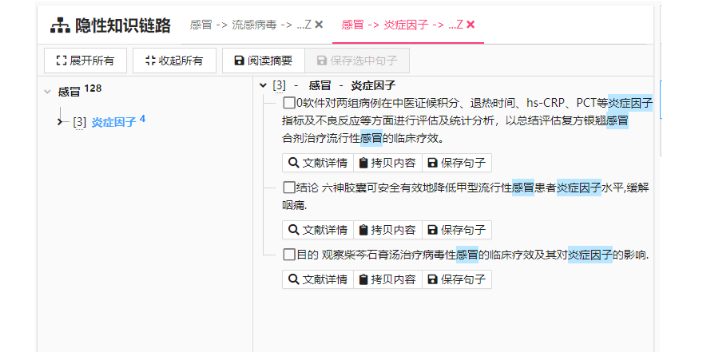
智慧導讀是一種利用人工智能技術進行個性化閱讀推薦的服務。它基于用戶的興趣、閱讀習慣和歷史記錄等信息,自動分析并推薦符合用戶興趣的文章、新聞、書籍等內容,幫助用戶更快速地獲取到自己感興趣的內容。智慧導讀的實現離不開大數據和機器學習技術,它需要對用戶的數據進行深入的分析和挖掘,并建立相應的推薦算法模型,才能提供準確、實用的推薦服務。在教育領域,智慧導讀也發(fā)揮著重要的作用。例如,在激發(fā)學生的閱讀興趣方面,智慧導讀可以根據學生的年齡階段和心理狀態(tài),提供具有吸引力的插圖或兒歌因素的讀物,以激發(fā)學生的閱讀興趣。同時,通過影視動畫、電影等多媒體形式,也可以幫助學生更加簡單地理解書中的內容,增強書本的吸引力。總的來說,智慧導讀以其個性化和智能化的特點,為用戶提供了更加便捷、高效的閱讀體驗,同時也為教育領域注入了新的活力和創(chuàng)新。安徽智慧導讀發(fā)現在語義關聯矩陣中,由起始入口詞選擇任意某個興趣點,系統(tǒng)會找出兩者之間潛在的5條隱性知識鏈路。
內容語義組織方面。利用AIGC技術進一步加強館藏學術資源、開放獲取學術資源等質量內容的細粒度加工、對象化表示,如實現對學術論文中研究方法與研究結果等細粒度內容的標注,更好地揭示語義知識內容。比如,在提高中華古籍資源的閱讀與利用效率方面,建立基于機器閱讀理解的古文事件抽取算法[44],利用大模型從海量古文史料中挖掘結構化知識。(2)多模態(tài)內容創(chuàng)建方面。在知識組織的基礎上,自動進行主題化、專題化文本分類,自動生成文本、圖像、視頻、音頻等多模態(tài)內容,實現多模態(tài)內容的語義關聯。結合用戶閱讀需求,還可以自動生成標題、摘要等推廣信息,進行個性化學術資源推薦,而且可以預測同類用戶的學術資源需求。比如,AIGC輔助整理、生成學習資料,可以幫助跨專業(yè)的學生快速了解入門課程和學習路徑,打破學生自身的認知邊界。
幫助用戶在海量信息中提高學術資源尋求效率是圖情領域一直關注的研究主題。從研究結果可以看出,目前傳統(tǒng)文獻數據庫ScienceDirect提供**文獻的關聯信息服務、Elsevier提供個性化推薦服務,新型學術平臺ConnectedPapers、AMiner、YewnoDiscover等利用知識圖譜、語義分析、自然語言處理、機器學習等技術為用戶帶來智能檢索與智能推薦的新體驗。借力AIGC技術,面向學術用戶的閱讀尋求情境,圖書館可以從內容語義組織、多模態(tài)內容創(chuàng)建及數據資源建設3個方面創(chuàng)新質量學術資源服務模式。上海半坡是專門為圖書館提供文獻知識服務的公司。
數智時代,圖書館應引入人工智能技術來實現個性化閱讀服務。首先,建立一個基于人工智能的平臺,用于收集并分析用戶的閱讀習慣、搜索歷史和互動反饋等數據。圖書館可以利用數據挖掘技術,如聚類分析和關聯規(guī)則,洞察用戶的閱讀偏好和興趣,如分析用戶在網站上的瀏覽路徑和停留時間,揭示用戶對特定主題或書籍的關注度;其次,依托于這些數據,圖書館可運用人工智能系統(tǒng),采用協同過濾和內容基推薦的機器學習算法,向用戶推薦可能感興趣的新書或內容;再次,圖書館還要運用自然語言處理技術,開發(fā)智能助手以增強用戶交互體驗。智能助手能夠理解用戶的查詢意圖,并提供相應的信息服務,如解答關于藏書的問題,協助預約或提醒還書時間。同時,智能助手通過文本或語音與用戶互動,可以使服務更便捷、更貼心。此外,通過深度學習技術,圖書館可以自動對大量資源展開分類和標記。圖書館運用圖像識別和文本分析技術,可以自動識別書籍內容分類,并分析用戶生成的內容,如書評,以深入了解用戶的需求和興趣;在實施過程中,圖書館需持續(xù)更新和維護技術,尤其要定期訓練機器學習模型,以確保系統(tǒng)與用戶行為變化同步。尤其是網絡技術、數字存儲和傳輸技術等的普及,數字圖書館應運而生。互聯網智慧導讀概況
上海半坡的遠程訪問服務能夠促使圖書館現有數字文獻館藏發(fā)揮更大的讀者服務效益。安徽智慧導讀發(fā)現
個性化閱讀推薦系統(tǒng)的設計始于高效且精確的數據采集、處理與分析。在智慧圖書館中,用戶每天進行搜索、閱讀和下載等互動行為均會產生大量數據。以大型智慧圖書館為例,其每月會新增數千份電子書和期刊,且數百萬用戶的日常活動會生成海量數據記錄,包括搜索查詢、點擊和下載等行為數據。這些數據是設計個性化閱讀推薦系統(tǒng)的基礎,需要收集和處理,以便后續(xù)進行分析和應用。數據采集必須***覆蓋用戶數據,包括用戶的注冊信息、借閱記錄、閱讀習慣,以及用戶與智慧圖書館資源的交互方式等。依托上述數據,個性化閱讀推薦系統(tǒng)可掌握用戶的基本興趣和偏好,鑒別用戶潛在的興趣領域和行為模式,從而為推薦給予數據方面的支持。安徽智慧導讀發(fā)現
- 提供科研學術助手簡介 2025-07-16
- 數字圖書館科研學術助手概況 2025-07-15
- 安徽智慧導讀發(fā)現 2025-07-15
- 哪個智慧導讀發(fā)現 2025-07-15
- 本地科研學術助手費用 2025-07-15
- 參考智慧導讀發(fā)現 2025-07-15
- 信息化科研學術助手排行榜 2025-07-15
- 怎樣科研學術助手發(fā)現 2025-07-15
- 質量科研學術助手平臺 2025-07-15
- 信息化科研學術助手優(yōu)勢 2025-07-14
- 中山市橫欄鎮(zhèn)海葬好處和壞處 2025-07-16
- 龍崗區(qū)三類醫(yī)療器械GMP車間設計公司哪家好 2025-07-16
- 上海港餅干進口報關流程 2025-07-16
- 寶山區(qū)第三方刻章價格查詢 2025-07-16
- 海寧凍品行業(yè)用友U9系統(tǒng)服務 2025-07-16
- 六合區(qū)電話廣告設計哪家好 2025-07-16
- 常州房地產拓客禮品印刷 2025-07-16
- 泗陽提供事故車托運24小時服務 2025-07-16
- 浦東新區(qū)電話會議及展覽服務便捷 2025-07-16
- 長寧區(qū)信息物流配送五星服務 2025-07-16